
آرایه های از نوع TreeMap یک راه کار مفید برای ذخیره و دسترسی به داده های مرتب شده هستند. آنها می توانند برای کاربردهای مختلفی مانند ذخیره داده های آماری، مرتب سازی لیست ها و ایجاد درخت ها استفاده شوند. در زبان برنامه نویسی کاتلین، آرایه های از نوع TreeMap یک آرایه از جفت های کلید-مقدار هستند که به صورت منظم مرتب شده اند. کلیدها باید قابل مقایسه باشند، و مقادیر می توانند از هر نوع باشند.زمان هایی ممکن است ما بخواهیم داده های خود را به همراه کلید در آرایه خود ذخیره کنیم در این زمان ها است که از آرایه های از نوع TreeMap استفاده میکنیم.
مطالب مرتبط : آموزش مقدماتی کاتلین از صفر تا صد
پیاده سازی آرایه های TreeMap در کاتلین
برای ایجاد یک آرایه از نوع TreeMap، از سازنده زیر استفاده می کنیم:
|
1 |
fun <K : Comparable<K>, V> TreeMap<K, V>(): TreeMap<K, V> |
این سازنده یک آرایه خالی از نوع TreeMap ایجاد می کند.
برای اضافه کردن یک جفت کلید-مقدار به یک آرایه از نوع TreeMap، از تابع زیر استفاده می کنیم
|
1 |
fun <K : Comparable<K>, V> TreeMap<K, V>.put(key: K, value: V): V |
این تابع جفت کلید-مقدار مشخص شده را به آرایه اضافه می کند و مقدار قبلی را با همان کلید برمی گرداند. اگر کلید قبلاً در آرایه وجود داشته باشد، مقدار قبلی با مقدار جدید جایگزین می شود.
برای حذف یک جفت کلید-مقدار از یک آرایه از نوع TreeMap، از تابع زیر استفاده می کنیم:
|
1 |
fun <K : Comparable<K>, V> TreeMap<K, V>.remove(key: K): V? |
این تابع جفت کلید-مقدار مشخص شده را از آرایه حذف می کند و مقدار قبلی را با همان کلید برمی گرداند. اگر کلید در آرایه وجود نداشته باشد، مقدار null برمی گردد.
برای دسترسی به یک جفت کلید-مقدار از یک آرایه از نوع TreeMap، از تابع زیر استفاده می کنیم:
|
1 |
fun <K : Comparable<K>, V> TreeMap<K, V>.get(key: K): V? |
این تابع مقدار جفت کلید-مقدار مشخص شده را برمی گرداند. اگر کلید در آرایه وجود نداشته باشد، مقدار null برمی گردد.
برای بررسی وجود یک کلید در یک آرایه از نوع TreeMap، از تابع زیر استفاده می کنیم:
|
1 |
fun <K : Comparable<K>, V> TreeMap<K, V>.containsKey(key: K): Boolean |
این تابع true را برمی گرداند اگر کلید مشخص شده در آرایه وجود داشته باشد، در غیر این صورت false را برمی گرداند.
برای بررسی وجود یک جفت کلید-مقدار در یک آرایه از نوع TreeMap، از تابع زیر استفاده می کنیم:
|
1 |
fun <K : Comparator<K>, V> TreeMap<K, V>.containsValue(value: V): Boolean |
این تابع true را برمی گرداند اگر مقدار مشخص شده در آرایه وجود داشته باشد، در غیر این صورت false را برمی گرداند.
برای پیمایش یک آرایه از نوع TreeMap، از حلقه for-in استفاده می کنیم:
|
1 2 3 |
for ((key, value) in treeMap) { // do something with key and value } |
این حلقه برای هر جفت کلید-مقدار در آرایه تکرار می شود.
چندیدن مثال از TreeMap
در اینجا یک مثال از نحوه استفاده از آرایه های از نوع TreeMap آورده شده است:
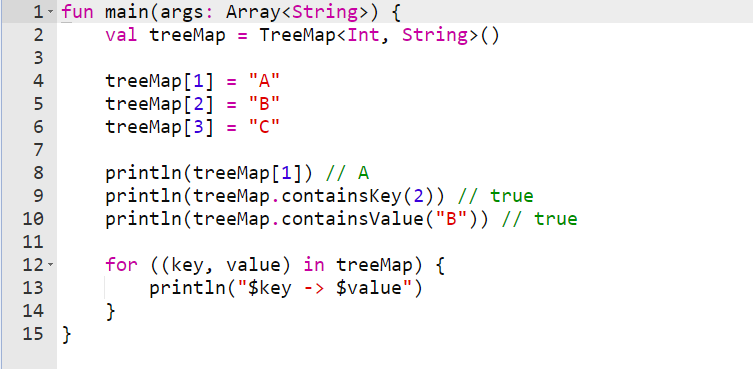
آرایه TreeMap در کاتلین
خروجی مثال بالا :

خروجی مثال آرایه TreeMap در کاتلین
مطالب مرتبط :نحوی مدیریت null در کاتلین به چه صورتی میباشد | آموزش مقدماتی کاتلین | درس دهم
چندین مثال دیگر TreeMap در برنامه نویسی کاتلین .
ذخیره داده های آماری
برای ذخیره داده های آماری مانند دما، وزن یا سن می توان از آرایه های از نوع TreeMap استفاده کرد. به عنوان مثال، در اینجا یک کد برای ذخیره داده های دما در یک آرایه از نوع TreeMap آورده شده است:
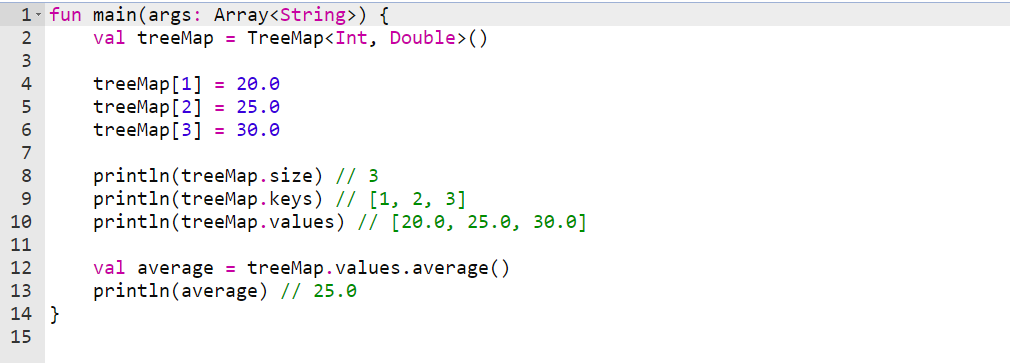
ذخیره داده های آماری
خروجی مثال بالا :

مرتب سازی لیست ها
برای مرتب سازی یک لیست می توان از یک آرایه از نوع TreeMap استفاده کرد. به عنوان مثال، در اینجا یک کد برای مرتب سازی یک لیست از اعداد در یک آرایه از نوع TreeMap آورده شده است:

مرتب سازی لیست ها

خروجی مثال بالا
ایجاد درخت ها
برای ایجاد یک درخت می توان از آرایه های از نوع TreeMap استفاده کرد. به عنوان مثال، در اینجا یک کد برای ایجاد یک درخت از اعداد در یک آرایه از نوع TreeMap آورده شده است:
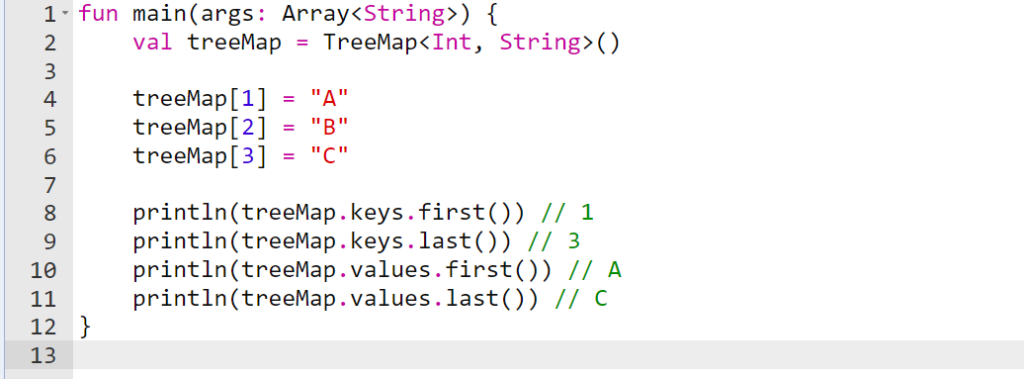
ایجاد درخت ها با TreeMap

خروجی مثال بالا
مطالب مرتبط: کلاس ها در کاتلین | آموزش مقدماتی کاتلین |درس نهم
تفاوت بین TreeMap و HashMap در کاتلین
ساختار داده:
- TreeMap: مبتنی بر درخت (معمولاً درخت قرمز و مشکی) است که داده ها را بر اساس کلیدها به صورت صعودی مرتب می کند.
- HashMap: مبتنی بر Hashing است که کلیدها را به یک سطل خاص بر اساس تابع Hash هدایت می کند.
دسترسی:
- TreeMap: پیدا کردن و پیمایش عنصر بر اساس کلیدها (به دلیل مرتب بودن) سریعتر است (زمان پیچیدگی O(log n)).
- HashMap: دسترسی مستقیم به یک عنصر با کلید مشخص بسیار سریع است (زمان پیچیدگی O(1) در حالت ایده آل).
اضافه کردن و حذف:
- TreeMap: اضافه کردن و حذف عناصر کمی کندتر از HashMap است (زمان پیچیدگی O(log n)).
- HashMap: اضافه کردن و حذف عناصر به طور کلی سریعتر است (زمان پیچیدگی O(1) در حالت ایده آل).
فضا:
- TreeMap: به دلیل ساختار درخت ممکن است حافظه بیشتری نسبت به HashMap مصرف کند.
- HashMap: به طور کلی حافظه کمتری مصرف می کند.
قابلیت مرتب سازی:
- TreeMap: داده ها به طور خودکار بر اساس کلیدها مرتب می شوند.
- HashMap: داده ها بر اساس کلیدها مرتب نیستند. برای مرتب سازی باید از روش های مرتب سازی خارجی استفاده شود.
کاربرد:
- TreeMap:
- وقتی نیاز به مرتب بودن داده ها برای پیمایش یا یافتن عناصر بر اساس ترتیب مشخصی دارید.
- وقتی می خواهید محدوده ای از داده ها (floor, ceiling) را پیدا کنید.
- HashMap:
- برای دسترسی سریع به عناصر براساس کلید (به استثنای موارد با تعداد برخوردهای زیاد).
- وقتی مرتب بودن داده ها مهم نیست.
خلاصه:
- TreeMap: انتخاب خوبی برای داده های مرتب شده و عملیات جستجوی ترتیبی است.
- HashMap: انتخاب خوبی برای دسترسی سریع به عناصر براساس کلید است.
مطالب مرتبط : HashMap در کاتلین چیست ؟
انتخاب بین TreeMap و HashMap به نیازهای خاص برنامه شما بستگی دارد. اگر مرتب بودن داده ها مهم است و نیاز به جستجوی ترتیبی دارید، TreeMap انتخاب خوبی است. اگر دسترسی سریع به عناصر براساس کلید مهم است و مرتب بودن داده ها اهمیتی ندارد، HashMap انتخاب خوبی است.




دیدگاهتان را بنویسید